

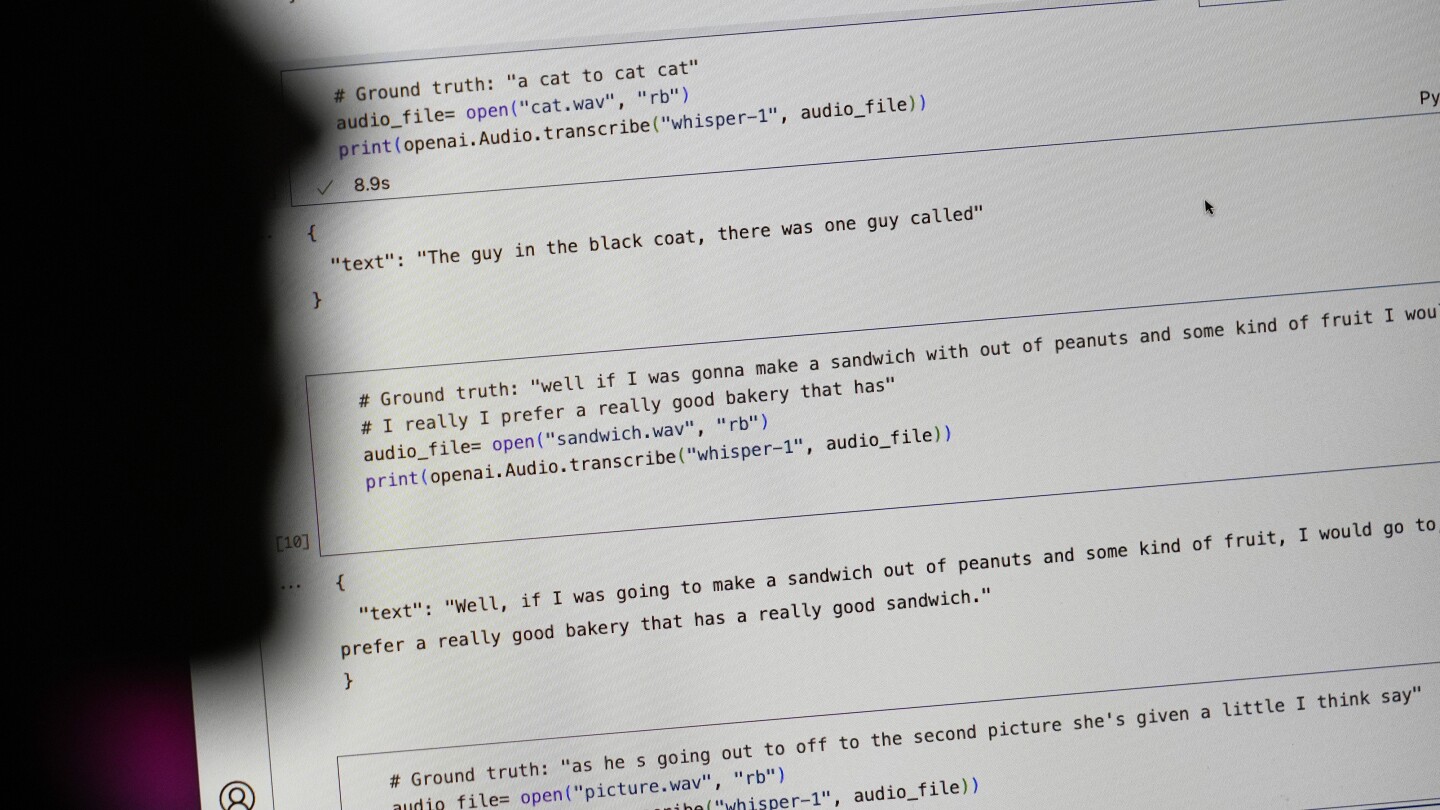
Tech behemoth OpenAI has touted its artificial intelligence-powered transcription tool Whisper as having near “human level robustness and accuracy.”
But Whisper has a major flaw: It is prone to making up chunks of text or even entire sentences, according to interviews with more than a dozen software engineers, developers and academic researchers. Those experts said some of the invented text — known in the industry as hallucinations — can include racial commentary, violent rhetoric and even imagined medical treatments.
Experts said that such fabrications are problematic because Whisper is being used in a slew of industries worldwide to translate and transcribe interviews, generate text in popular consumer technologies and create subtitles for videos.
More concerning, they said, is a rush by medical centers to utilize Whisper-based tools to transcribe patients’ consultations with doctors, despite OpenAI’ s warnings that the tool should not be used in “high-risk domains.”
I’ve read that this is only going to continue to happen (and get worse) because we’re basically out of human-generated training data that’s publicly available on the internet, so models are being trained on content generated by other models. They literally make shit up constantly, and every generation gets dumber and dumber until they can’t even stay on topic or complete a coherent sentence anymore.
Edit: Here’s the post I was reading, written by Ed Zitron. It’s pretty well written and thoughtful, though it is an opinion article from some guy’s blog at the end of the day. Also, by “generation,” I mean generations of AI, not generations of people.
Odd that GPT (and of course all the LLMs too) only got better so far…
The architecture changed, there is still progress to be made there. But LLMs will forever be stuck in 2021, all data afterwards is tainted. Not a lot has been added.
In fact, Whisper was developed to transcribe videos for more training data, because they ran out of text data. These bad transcriptions are in newer models.