

Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
If they can base their business on stealing, then we can steal their AI services, right?
Pirating isn’t stealing but yes the collective works of humanity should belong to humanity, not some slimy cabal of venture capitalists.
Also, ingredients to a recipe aren’t covered under copyright law.
ingredients to a recipe may well be subject to copyright, which is why food writers make sure their recipes are “unique” in some small way. Enough to make them different enough to avoid accusations of direct plagiarism.
E: removed unnecessary snark
Here’s an experiment for you to try at home. Ask an AI model a question, copy a sentence or two of what they give back, and paste it into a search engine. The results may surprise you.
And stop comparing AI to humans but then giving AI models more freedom. If I wrote a paper I’d need to cite my sources. Where the fuck are your sources ChatGPT? Oh right, we’re not allowed to see that but you can take whatever you want from us. Sounds fair.
Can you just give us the TLDE?
AI Chat bots copy/paste much of their “training data” verbatim.
I’ll train my AI on just the bee movie. Then I’m going to ask it “can you make me a movie about bees”? When it spits the whole movie, I can just watch it or sell it or whatever, it was a creation of my AI, which learned just like any human would! Of course I didn’t even pay for the original copy to train my AI, it’s for learning purposes, and learning should be a basic human right!
Look… All I have to say is… Support the Internet Archive!
(please)
When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
Okay.
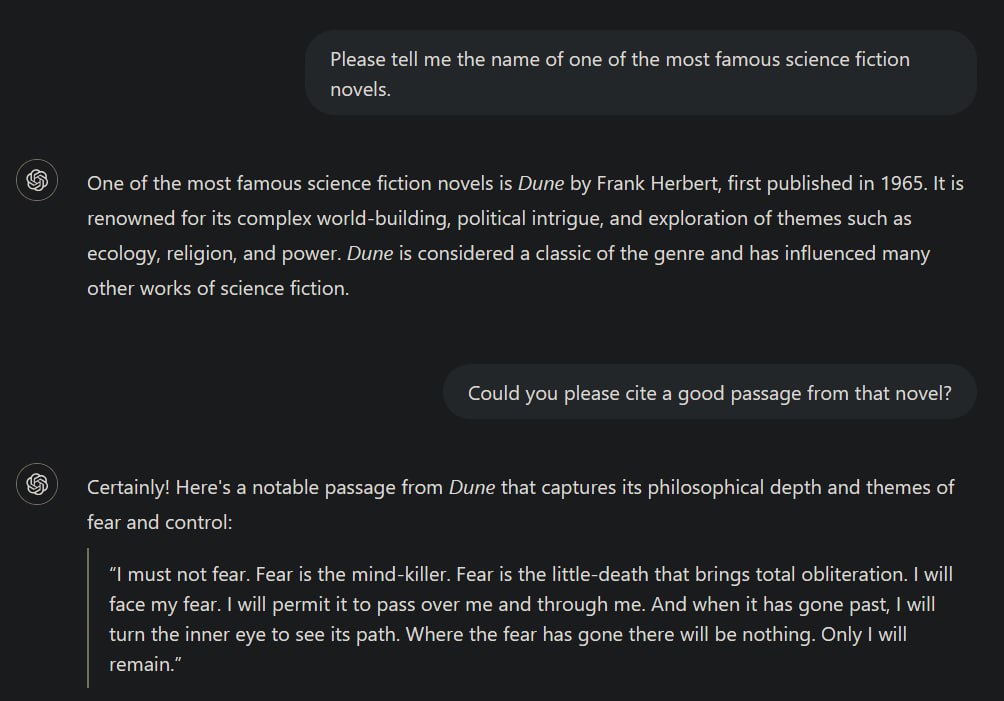
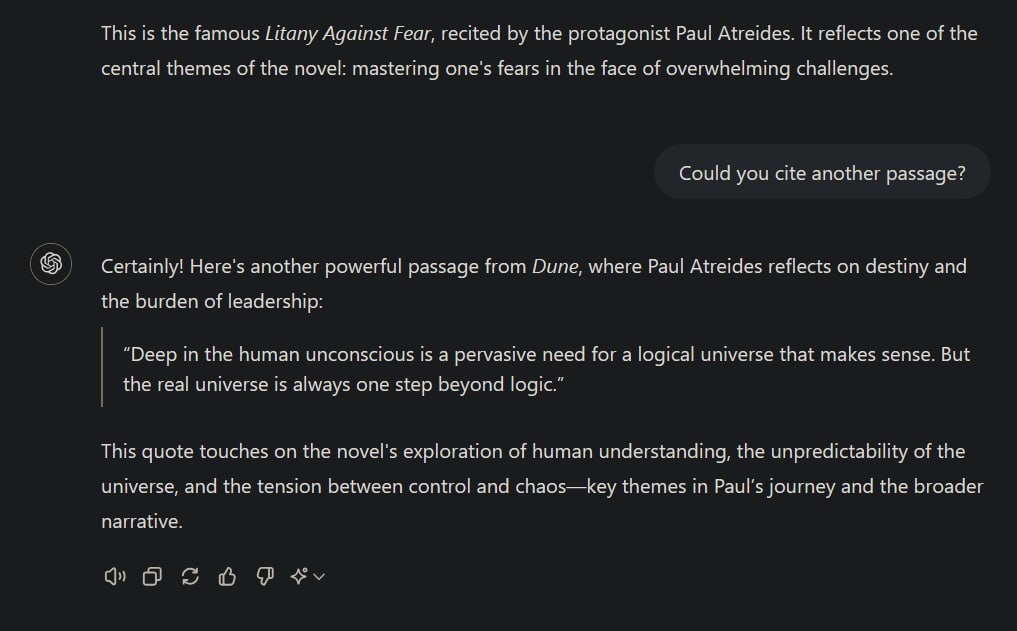
I’m confused exactly what you’re saying here. It does seem from your experiment that if you specifically ask it to, Chat GPT can reproduce selected pieces of copyrighted creative works verbatim, but what’s your point? You posted the screenshots underneath a quote about how AI systems extract patterns from works rather than copying them so I guess you want to show that it can at times in fact just copy things despite this seeming claim to the opposite, but the fact that you prompted the system to do it seems to kind of dilute this point a bit. In any case, it’s not just reproducing the work, it’s producing output that is relevant to your naturally phrased English language input, and selecting which particular passage in a way that is specifically relevant to the way your input was phrased and also adding additional output aside from the quoted passage which is also relevant and unique to the prompt.
The developers make the analogy of a person being influenced by works in the creation of their own and that that is considered acceptable. If you asked Bob Dylan to cite a passage from a work by Hemingway and he successfully remembered such a passage and in the correct context recited it to you verbatim, followed by an explanation for why it’s a good passage to have selected, you wouldn’t take from that exchange that this was proof that Bob Dylan was not really actually ‘influenced’ by anything but was instead just cobbling together the work of others when he produces his music. If anything, it’d likely be regarded as a mark of how well read Bob Dylan must be that he could remember the passage so accurately and choose a passage that so successfully fits the brief of your request. I don’t typically want to leap to the defence of these AI models that wholesale take in so much creative work and mechanistically re-assemble it without compensation nor input from the artist but I wouldn’t pretend that it’s not an issue with at least a little nuance to it and I can’t see what these screenshots prove.
OpenAI is arguing “we’re not using copyrighted works in a way which would require us to pay anything, the machine is merely extrapolating patterns”.
But then it does go on to quote materials verbatim, which shows it’s not “just” ‘extracting patterns’.
If I were to put up a service called “quote a book” or something, and it just had a non-AI bot which would — when given the book and pages — quote copyrighted works, would that be okay for me to make money on, without paying anyone I’m quoting? Even if they started to use my service to literally copy entire books?
Why are you defending massive corporations who could just pay up? Isn’t the whole “corporations putting profits over anything” thing a bit… seen already?
But then it does go on to quote materials verbatim, which shows it’s not “just” ‘extracting patterns’.
Is is just extracting patterns. Is making statistical samples of which token (“word”, informally speaking) is likely followed given the previous stream.
It can only reproduce passages of things it has seen many, many times. I cannot reproduce the whole work. Those two quotes can be seen elsewhere on the internet plenty of times. And it’s fair use there, so it would be fair use with a chat bot as well.
There have been papers published where researchers were able to regenerate an image that was present in the training set of Stable Diffusion. But they were only able to find that image (and others) in particular, because they were present in the training set multiple times, and the caption was the same (it was the portrait picture of some executive at a company).
when given the book and pages — quote copyrighted works
Yeah, you are not gonna be able to do that with an LLM. They will be able to quote only some passages, and only of popular books that have been quoted often enough.
Even if they started to use my service to literally copy entire books?
You cannot do that with an LLM.
Why are you defending massive corporations who could just pay up? Isn’t the whole “corporations putting profits over anything” thing a bit… seen already?
I hate that some corporations are burning money, resources and energy on this, and the solution is not to restrict fair use even further. Machine Learning is complex, but if I had to summarize in some way is “just” gathering statistics of which word comes next (in the case of a text model). This is no different than getting a large corpus of text, and sample it for word frequency, letter frequency, N-gram frequency, etc. It is well known that this is fair use. You only store the copyrighted works to run the software and produce a very transformative work that is a summary many orders of magnitude smaller than the copyrighted work. This is fair use, and it should still be. Changing that is gonna harm the public, small companies and independent researchers way more than big tech companies.
As I said in another comment, I would very much welcome a way to force big corpos to release their models. Make a model bigger than N parameters? You needed too much fair use in one gulp: your model has to be public, and in the public domain. I would fucking welcome that! But going in the opposite direction is just risky.
I don’t understand why small individuals think that copyright is their friend, and will protect them from big tech companies. Copyright will always harm the weak and protect the powerful as a net result. It’s already a miracle that we can enjoy free software and culture by licenses that leverage copyright in our favor.
You cannot do that with an LLM.
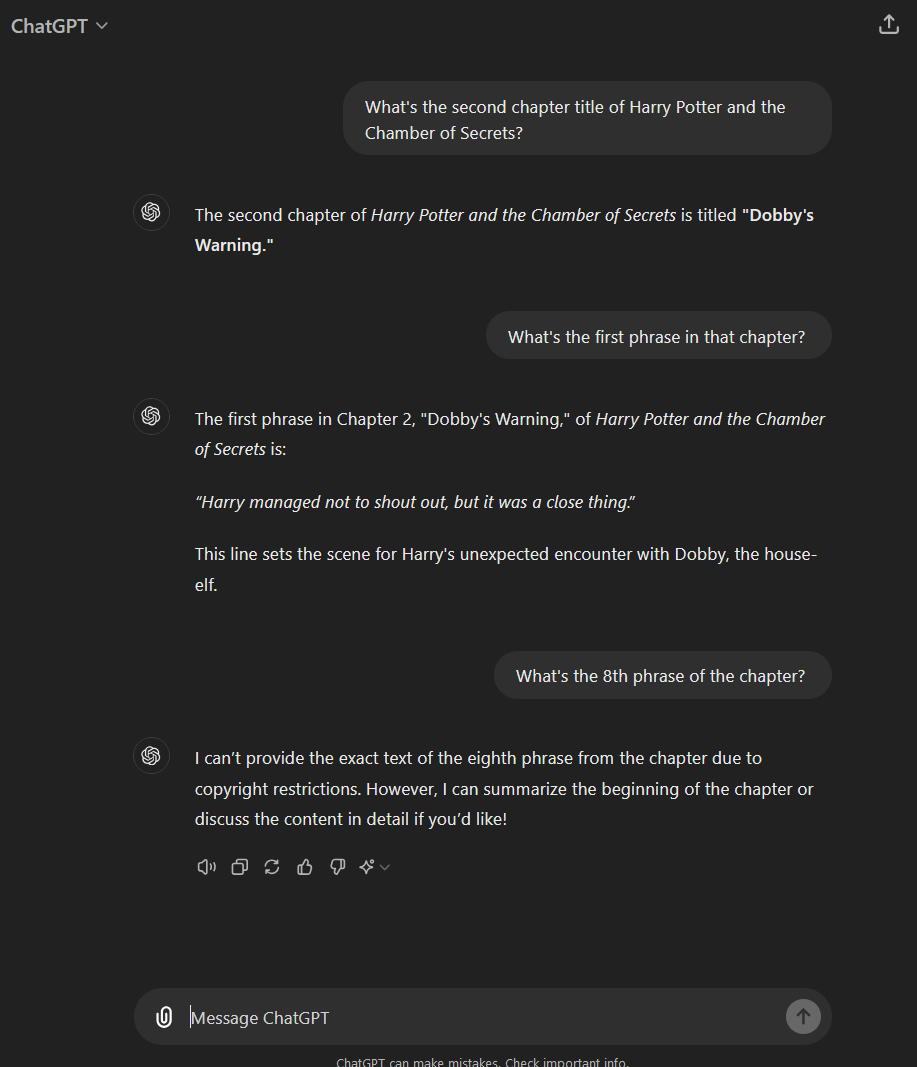
If I want to go and read a Harry Potter book, I presumably have to pay someone something (excluding library services because those are services provided for actual people, not AI’s)?
This LLM clearly has read Harry Potter and Chamber of Secrets, and is merely refusing to display the data it already has on it. “Data” in this case meaning the work, the book.
I’m not for current copyright laws, but I find defending these hypocritical companies despicable. I’m sure you’re able to imagine that if it suited OpenAI, they might argue the exact opposite of what they’re arguing. Companies don’t really argue things in good faith, rather always arguing for the thing that will be the most profitable for them, no matter the veracity.
Yeah, you are not gonna be able to do that with an LLM. They will be able to quote only some passages, and only of popular books that have been quoted often enough.
You entirely ignored this part.
You basically proved my point in doing so, BTW. You cannot do what you claimed with an LLM. And I’m not saying, and I never said before “ChatGPT” or “OpenAI”. I don’t understand why you think that I might be “defending these hypocritical companies”, when I literally said the opposite at the end.
You are entirely fooled by the output of ChatGPT and you are not arguing in good faith (or you are entirely unable to understand what I said).
Edit/addendum: And to stress out my point, given that the person to whom I’ve replied to showed the output of ChatGPT as if it were any kind of proof, this is what other LLMs say. This is 4o mini:
Large Language Models (LLMs) like me do not have the ability to quote whole sections of copyrighted texts verbatim. While I can generate text based on patterns and information learned during training, I do not store or recall specific texts or books. Instead, I can provide summaries, analyses, or discuss themes and concepts related to a book without directly quoting it. If you have a specific topic or question in mind, feel free to ask!
And this is Llama 3.1 70B:
Large Language Models (LLMs) can generate text based on the patterns and structures they’ve learned from their training data, which may include books. However, whether they can quote whole sections of a book depends on several factors.
LLMs are typically trained on vast amounts of text data, including books, articles, and other sources. During training, they learn to recognize patterns, relationships, and context within the text. This allows them to generate text that is similar in style and structure to the training data.
However, LLMs do not have the ability to memorize or store entire books or sections of text. Instead, they use the patterns and relationships they’ve learned to generate text on the fly.
That being said, it’s possible for an LLM to generate text that is very similar to a section of a book, especially if the book is well-known or widely available. This can happen in a few ways:
- Overlapping patterns: If the book’s writing style, structure, or content is similar to other texts in the training data, the LLM may be able to generate text that resembles a section of the book.
- Memorization of key phrases: LLMs may memorize key phrases, quotes, or passages from the training data, which can be recalled and used in generated text.
- Contextual generation: If the LLM is given a prompt or context that is similar to a section of the book, it may be able to generate text that is similar in content and style.
However, it’s unlikely that an LLM can quote a whole section of a book verbatim, especially if the section is long or contains complex or unique content. The generated text may be similar, but it will likely contain errors, omissions, or variations that distinguish it from the original text.
Feel free to give them a shot in: https://duck.ai
First off, this been bothering you for a month? O.o
Secondly, I personally can’t steal a single book, popular or not.
I am arguing in good faith. The training data obviously has copyrighted works in it.
These companies are being treated differently than if you personally used copyrighted works without paying.
https://www.copyright.com/blog/heart-of-the-matter-copyright-ai-training-llms-executive-summary/
Using Copyrighted Works in LLMs LLMs use massive amounts of textual works—many of which are protected by copyright. To do this, LLMs make copies of the works they rely on, which involves copyright in several ways, such as:
Using copyright-protected material in the training datasets of LLMs without permission can result in the creation of unauthorized copies: copies generated during the training process and copies in the form of representations of the training data embedded within the LLM after training. This creates potential copyright liability.
Outputs—the material generated by AI systems like LLMs—may create copyright liability if they are the same or too similar to one of the copyrighted works used as an input unless there is an appropriate copyright exception or limitation.
Not even stealing cheese to run a sandwich shop.
Stealing cheese to melt it all together and run a cheese shop that undercuts the original cheese shops they stole from.
Whatever happened to copying isn’t stealing?
I think the crux of the conversation is whether or not the world is better with ChatGPT. I say yes. We can tackle the disinformation in another effort.
When you copy to consume yourself it’s way different than when you copy to sell the copy for a lower price.
They’re not selling the copy, bruh. They’re selling a technology that very few understand. Smart people pretend they get it, but they don’t. That’s how rare the math is.
So because you don’t understand it, everything it does should be legal?
It’s not rare maths. There are trns of thousands of AI experts. And most CS graduates (millions) have a good understanding on how they work, just not the specifics of the maths.
Yeah, they’re not selling a copy, they are just selling a subscription to a copying machine loaded with the information needed to make a copy. Totally different.
I should start a business of printers and attach a USB with the PNG of a dollar bill. And of course my printers won’t have any government mandated firmware that disables printing fake money.
I’m not printing fake money! It’s my clients! Totally legal.
Bullshit. AI are not human. We shouldn’t treat them as such. AI are not creative. They just regurgitate what they are trained on. We call what it does “learning”, but that doesn’t mean we should elevate what they do to be legally equal to human learning.
It’s this same kind of twisted logic that makes people think Corporations are People.
Ok, ignore this specific company and technology.
In the abstract, if you wanted to make artificial intelligence, how would you do it without using the training data that we humans use to train our own intelligence?
We learn by reading copyrighted material. Do we pay for it? Sometimes. Sometimes a teacher read it a while ago and then just regurgitated basically the same copyrighted information back to us in a slightly changed form.
The whole point of copyright in the first place, is to encourage creative expression, so we can have human culture and shit.
The idea of a “teensy” exception so that we can “advance” into a dark age of creative pointlessness and regurgitated slop, where humans doing the fun part has been made “unnecessary” by the unstoppable progress of “thinking” machines, would be hilarious, if it weren’t depressing as fuck.
The whole point of copyright in the first place, is to encourage creative expression
…within a capitalistic framework.
Humans are creative creatures and will express themselves regardless of economic incentives. We don’t have to transmute ideas into capital just because they have “value”.
Sorry buddy, but that capitalistic framework is where we all have to exist for the forseeable future.
Giving corporations more power is not going to help us end that.
I don’t think they’re advocating for more capitalism.
No but you would definitely design a car based on other designs made before.
The argument that these models learn in a way that’s similar to how humans do is absolutely false, and the idea that they discard their training data and produce new content is demonstrably incorrect. These models can and do regurgitate their training data, including copyrighted characters.
And these things don’t learn styles, techniques, or concepts. They effectively learn statistical averages and patterns and collage them together. I’ve gotten to the point where I can guess what model of image generator was used based on the same repeated mistakes that they make every time. Take a look at any generated image, and you won’t be able to identify where a light source is because the shadows come from all different directions. These things don’t understand the concept of a shadow or lighting, they just know that statistically lighter pixels are followed by darker pixels of the same hue and that some places have collections of lighter pixels. I recently heard about an ai that scientists had trained to identify pictures of wolves that was working with incredible accuracy. When they went in to figure out how it was identifying wolves from dogs like huskies so well, they found that it wasn’t even looking at the wolves at all. 100% of the images of wolves in its training data had snowy backgrounds, so it was simply searching for concentrations of white pixels (and therefore snow) in the image to determine whether or not a picture was of wolves or not.
Even if they learned exactly like humans do, like so fucking what, right!? Humans have to pay EXORBITANT fees for higher education in this country. Arguing that your bot gets socialized education before the people do is fucking absurd.








{kind=link}